Spotify, TidyModels and Shiny - a workflow
A Logistic Regression model using Spotify data
I recently came across Julia Silge’s excellent online course around the use of the TidyModels package in R, and from there to the suite of resources on the dedicated TidyModels website. Both contain short exercises the demonstrate the basics of the package. I decided to create a small-scale project around that learning that also combined some other skills and techniques I had previous picked up.
I came up with the idea of a project that would gather data from the Spotify API, perform some EDA (exploratory data analysis) and visualisation, and then use that as the basis for a simple Logistic Regression model that could make predictions about the relative age of songs. I then produced a small Shiny app that would enabling users to interact with the model by entering songs to see the results of predictions.
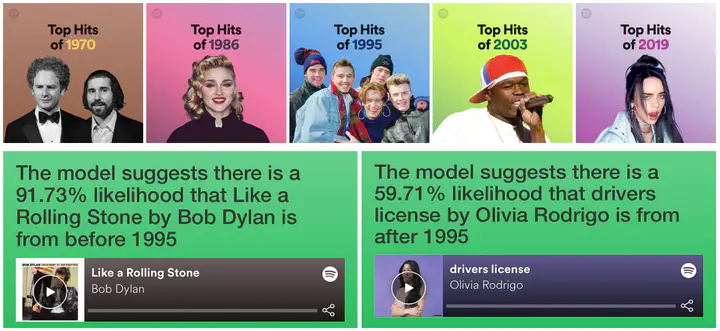
The model was trained on ~5,000 hit songs recorded between 1970 and 2019. The aim was to classify songs as being from either before or after the mid-point year of 1995. The model uses metrics available from Spotify’s API - including tempo, duration, ‘valence’, ‘acousticness’, etc. - to make predictions. You can see a live, working version of the app here.
In testing, the model achieved ~85% accuracy but tended to struggle most with songs recorded in years immediately either side of 1995. It also has difficulty with songs that exemplify certain genres (e.g. jazz, country), so it can produce some odd predictions! In the main, however, it seems to be pretty accurate – although the ‘fun’ in playing with it is largely in finding songs that fool it. In truth, the aim of the process was not to create a model that worked 100% of the time – and, in any case, who really needs to know if a song is from before or after 1995? – rather, it was to see how the TidyModels package could be incorporated into a broader workflow that might be useful to students and other people learning some fundamental skills with R. I think the workflow hangs together quite nicely, and makes for a nice mini-project.
All of the code required to recreate that workflow is available on my GitHub page, from gathering Spotify data to development of the Shiny app. My next steps with this work will be to look at manner in which Julia Silge produced the mini-course above, and to see if my Github repo can be developed into something similar using decampr and binder.
Dr Craig Hamilton
My research interests include popular music, digital humanities and online cultures.